 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgorithmic Recourse of In-Context Learning for Tabular Data
May 29, 2026As predictive models are increasingly deployed in high-stakes settings such as credit approval, there is a growing need for post-hoc methods that provide recourse to affected individuals. Many such models operate on tabular data, where features correspond to real-world attributes. Recently, in-context learning (ICL) has enabled large language models to perform tabular prediction by conditioning on labeled examples at inference time, without explicit training. However, algorithmic recourse for tabular decision-making under ICL remains largely unexplored. In this work, we present the first study of algorithmic recourse for tabular data under ICL. We carry out a theoretical analysis, showing that recourse remains well-defined and bounded, and we characterize how recourse converges toward classical solutions as the context size increases. In practice, we propose a novel zeroth-order recourse framework, Adaptive Subspace Recourse for In-Context Learning (ASR-ICL), that efficiently generates actionable and sparse recourse for black-box ICL models. The proposed framework naturally extends to multi-class tabular tasks. Experiments across multiple real-world datasets and models demonstrate that ASR-ICL achieves recourse quality comparable to existing methods with fewer queries and empirically confirm the predicted convergence behavior, supporting our theoretical analysis.
Matryoshka Concept Bottleneck Models
May 20, 2026Concept Bottleneck Models (CBMs) have emerged as a prominent paradigm for interpretable deep learning, learning by grounding predictions in human-understandable concepts. However, their practical deployment is hindered by the high cost of test-time intervention, as correcting model errors typically requires human experts to manually inspect and verify a large set of predicted concepts. Existing approaches suffer from a fundamental structural limitation: they either adopt a single static concept set, forcing experts to exhaustively annotate concepts and incurring prohibitive intervention costs, or train multiple models tailored to different concept budgets, resulting in substantial computational and maintenance overhead. To address this challenge, we propose the Matryoshka Concept Bottleneck Model (MCBM), a unified architecture that enables adaptive concept utilization within a single model. Inspired by Matryoshka Representation Learning, MCBM organizes concepts into a nested hierarchy based on maximum relevance and minimum redundancy, allowing inference at multiple levels of conceptual granularity without retraining. Theoretically, we show that MCBM reduces the expected intervention costs from linear to logarithmic order, $O(\log K)$, while guaranteeing monotonic performance improvement. Empirically, extensive experiments demonstrate that MCBM matches the performance of independently trained models while enabling dynamic and efficient expert interaction.
AR1-ZO: Topology-Aware Rank-1 Zeroth-Order Queries for High-Rank LoRA Fine-Tuning
May 19, 2026Zeroth-order (ZO) optimization enables large-language-model fine-tuning without storing backpropagation activations, while LoRA supplies compact trainable adapters. Combining them creates a rank paradox: increasing LoRA rank improves adapter capacity, but standard two-point ZO either perturbs a rank-dependent number of coordinates or, under atomwise updates, can make the finite-difference signal unobservable. This paper shows that the bottleneck is a measurement-topology problem rather than a need for an external subspace. LoRA already decomposes into matched rank-$1$ atoms, each a complete factor-coordinate block of dimension $d_\text{out}+d_\text{in}$. Querying one atom per step keeps the stored adapter rank $r$ while removing $r$ from the single-query perturbation dimension. The naive atomwise query is still miscalibrated: if it inherits canonical LoRA scaling $α/r$, the active finite-difference signal shrinks as $1/r$ and the active finite-difference signal-to-noise ratio (FD-SNR) as $1/r^2$, producing directional collapse under a fixed residual evaluation-noise floor. AR1-ZO pairs alternating rank-$1$ atom queries with topology-aware scaling $γ=αr$, restoring rank-invariant active signal without auxiliary bases, activation hooks, curvature estimates, or extra forward queries. Theory proves atom minimality, rank-independent active query dimension, directional collapse and restoration, and the remaining rank dependence as an amortized coverage cost. Experiments on OPT and Qwen3 models validate the signal mechanism and show that AR1-ZO makes high-rank LoRA effective among matched-budget ZO methods under the standard two-forward-pass query budget.
Reference-Sampled Boltzmann Projection for KL-Regularized RLVR: Target-Matched Weighted SFT, Finite One-Shot Gaps, and Policy Mirror Descent
May 04, 2026Online reinforcement learning with verifiable rewards (RLVR) turns checkable outcomes into a scalable training signal, but it keeps rollout generation, verifier scoring, and reference-policy evaluations on the optimization path. Static weighted supervised fine-tuning (SFT) on precomputed rollouts seems to remove this bottleneck, yet a weighted likelihood is not specified by rewards alone: its sampler and weights induce the policy being fit. This paper identifies the reference-sampled weighted-SFT objective whose induced policy equals the fixed-reference KL-regularized RLVR optimizer. The optimizer is the standard Boltzmann target policy, obtained by exponentially tilting the reference policy by verifier reward. Matching a weighted-SFT induced policy to this target forces density-ratio weights; in the reference-sampled subclass, this reduces uniquely, up to prompt scaling, to the prompt-normalized Boltzmann weight $\exp(r(x,y)/β)/Z(x)$. BOLT, a Boltzmann-Targeted SFT procedure, is the empirical estimator of this projection. The finite one-shot analysis separates the exact stored-support price $β\log(1/π^*(S_N\mid x))$ from partition estimation, effective-sample-size variance, generalization, optimization, and approximation errors. This decomposition explains why extra SFT epochs cannot repair missing reference-policy coverage and exposes the temperature--coverage--variance frontier. When coverage needs adaptive sampling, refreshed Boltzmann projections become KL policy mirror descent; finite inner solves enter as additive drift from the exact mirror step. Single-run Qwen experiments provide projection evidence for the target-matched weight, one-shot saturation, refreshed-sampler gains, and optimization-time savings, within the stated single-run scope.
X-World: Controllable Ego-Centric Multi-Camera World Models for Scalable End-to-End Driving
Mar 20, 2026Scalable and reliable evaluation is increasingly critical in the end-to-end era of autonomous driving, where vision--language--action (VLA) policies directly map raw sensor streams to driving actions. Yet, current evaluation pipelines still rely heavily on real-world road testing, which is costly, biased toward limited scenario coverage, and difficult to reproduce. These challenges motivate a real-world simulator that can generate realistic future observations under proposed actions, while remaining controllable and stable over long horizons. We present X-World, an action-conditioned multi-camera generative world model that simulates future observations directly in video space. Given synchronized multi-view camera history and a future action sequence, X-World generates future multi-camera video streams that follow the commanded actions. To ensure reproducible and editable scene rollouts, X-World further supports optional controls over dynamic traffic agents and static road elements, and retains a text-prompt interface for appearance-level control (e.g., weather and time of day). Beyond world simulation, X-World also enables video style transfer by conditioning on appearance prompts while preserving the underlying action and scene dynamics. At the core of X-World is a multi-view latent video generator designed to explicitly encourage cross-view geometric consistency and temporal coherence under diverse control signals. Experiments show that X-World achieves high-quality multi-view video generation with (i) strong view consistency across cameras, (ii) stable temporal dynamics over long rollouts, and (iii) high controllability with strict action following and faithful adherence to optional scene controls. These properties make X-World a practical foundation for scalable and reproducible evaluation.
Retrieval-Infused Reasoning Sandbox: A Benchmark for Decoupling Retrieval and Reasoning Capabilities
Jan 29, 2026Despite strong performance on existing benchmarks, it remains unclear whether large language models can reason over genuinely novel scientific information. Most evaluations score end-to-end RAG pipelines, where reasoning is confounded with retrieval and toolchain choices, and the signal is further contaminated by parametric memorization and open-web volatility. We introduce DeR2, a controlled deep-research sandbox that isolates document-grounded reasoning while preserving core difficulties of deep search: multi-step synthesis, denoising, and evidence-based conclusion making. DeR2 decouples evidence access from reasoning via four regimes--Instruction-only, Concepts (gold concepts without documents), Related-only (only relevant documents), and Full-set (relevant documents plus topically related distractors)--yielding interpretable regime gaps that operationalize retrieval loss vs. reasoning loss and enable fine-grained error attribution. To prevent parametric leakage, we apply a two-phase validation that requires parametric failure without evidence while ensuring oracle-concept solvability. To ensure reproducibility, each instance provides a frozen document library (drawn from 2023-2025 theoretical papers) with expert-annotated concepts and validated rationales. Experiments across a diverse set of state-of-the-art foundation models reveal substantial variation and significant headroom: some models exhibit mode-switch fragility, performing worse with the Full-set than with Instruction-only, while others show structural concept misuse, correctly naming concepts but failing to execute them as procedures.
Controllable Concept Bottleneck Models
Jan 01, 2026Concept Bottleneck Models (CBMs) have garnered much attention for their ability to elucidate the prediction process through a human-understandable concept layer. However, most previous studies focused on static scenarios where the data and concepts are assumed to be fixed and clean. In real-world applications, deployed models require continuous maintenance: we often need to remove erroneous or sensitive data (unlearning), correct mislabeled concepts, or incorporate newly acquired samples (incremental learning) to adapt to evolving environments. Thus, deriving efficient editable CBMs without retraining from scratch remains a significant challenge, particularly in large-scale applications. To address these challenges, we propose Controllable Concept Bottleneck Models (CCBMs). Specifically, CCBMs support three granularities of model editing: concept-label-level, concept-level, and data-level, the latter of which encompasses both data removal and data addition. CCBMs enjoy mathematically rigorous closed-form approximations derived from influence functions that obviate the need for retraining. Experimental results demonstrate the efficiency and adaptability of our CCBMs, affirming their practical value in enabling dynamic and trustworthy CBMs.
FutureX: Enhance End-to-End Autonomous Driving via Latent Chain-of-Thought World Model
Dec 12, 2025



In autonomous driving, end-to-end planners learn scene representations from raw sensor data and utilize them to generate a motion plan or control actions. However, exclusive reliance on the current scene for motion planning may result in suboptimal responses in highly dynamic traffic environments where ego actions further alter the future scene. To model the evolution of future scenes, we leverage the World Model to represent how the ego vehicle and its environment interact and change over time, which entails complex reasoning. The Chain of Thought (CoT) offers a promising solution by forecasting a sequence of future thoughts that subsequently guide trajectory refinement. In this paper, we propose FutureX, a CoT-driven pipeline that enhances end-to-end planners to perform complex motion planning via future scene latent reasoning and trajectory refinement. Specifically, the Auto-think Switch examines the current scene and decides whether additional reasoning is required to yield a higher-quality motion plan. Once FutureX enters the Thinking mode, the Latent World Model conducts a CoT-guided rollout to predict future scene representation, enabling the Summarizer Module to further refine the motion plan. Otherwise, FutureX operates in an Instant mode to generate motion plans in a forward pass for relatively simple scenes. Extensive experiments demonstrate that FutureX enhances existing methods by producing more rational motion plans and fewer collisions without compromising efficiency, thereby achieving substantial overall performance gains, e.g., 6.2 PDMS improvement for TransFuser on NAVSIM. Code will be released.
Graph-Guided Dual-Level Augmentation for 3D Scene Segmentation
Jul 30, 20253D point cloud segmentation aims to assign semantic labels to individual points in a scene for fine-grained spatial understanding. Existing methods typically adopt data augmentation to alleviate the burden of large-scale annotation. However, most augmentation strategies only focus on local transformations or semantic recomposition, lacking the consideration of global structural dependencies within scenes. To address this limitation, we propose a graph-guided data augmentation framework with dual-level constraints for realistic 3D scene synthesis. Our method learns object relationship statistics from real-world data to construct guiding graphs for scene generation. Local-level constraints enforce geometric plausibility and semantic consistency between objects, while global-level constraints maintain the topological structure of the scene by aligning the generated layout with the guiding graph. Extensive experiments on indoor and outdoor datasets demonstrate that our framework generates diverse and high-quality augmented scenes, leading to consistent improvements in point cloud segmentation performance across various models.
DriveGEN: Generalized and Robust 3D Detection in Driving via Controllable Text-to-Image Diffusion Generation
Mar 14, 2025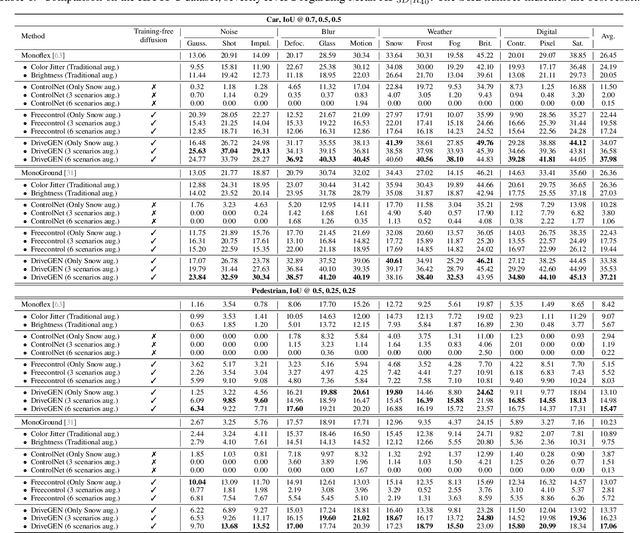


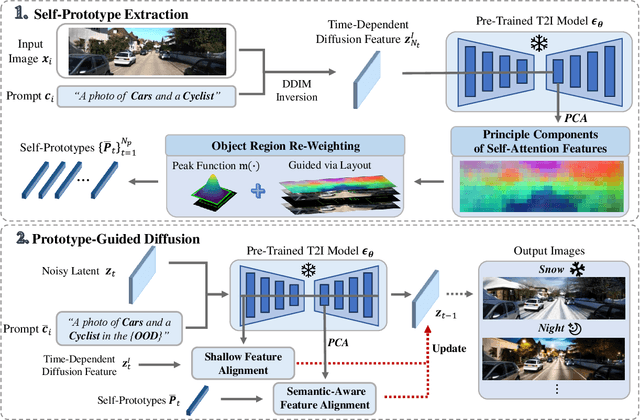
In autonomous driving, vision-centric 3D detection aims to identify 3D objects from images. However, high data collection costs and diverse real-world scenarios limit the scale of training data. Once distribution shifts occur between training and test data, existing methods often suffer from performance degradation, known as Out-of-Distribution (OOD) problems. To address this, controllable Text-to-Image (T2I) diffusion offers a potential solution for training data enhancement, which is required to generate diverse OOD scenarios with precise 3D object geometry. Nevertheless, existing controllable T2I approaches are restricted by the limited scale of training data or struggle to preserve all annotated 3D objects. In this paper, we present DriveGEN, a method designed to improve the robustness of 3D detectors in Driving via Training-Free Controllable Text-to-Image Diffusion Generation. Without extra diffusion model training, DriveGEN consistently preserves objects with precise 3D geometry across diverse OOD generations, consisting of 2 stages: 1) Self-Prototype Extraction: We empirically find that self-attention features are semantic-aware but require accurate region selection for 3D objects. Thus, we extract precise object features via layouts to capture 3D object geometry, termed self-prototypes. 2) Prototype-Guided Diffusion: To preserve objects across various OOD scenarios, we perform semantic-aware feature alignment and shallow feature alignment during denoising. Extensive experiments demonstrate the effectiveness of DriveGEN in improving 3D detection. The code is available at https://github.com/Hongbin98/DriveGEN.